Fingerprinting Images to Improve Page Load Speed
As websites and web applications expand their visual richness and functionality, optimizing for page speed becomes more critical. Because static assets are such a large part of page speed and don’t change often, it’s important to reload them from a cache (either the user’s browser or a CDN) rather than going back to the originating web server each time.
Using a combination of HTTP headers at the server level and fingerprinting at the file level allows you to set an effectively infinite expiration date (so that unchanged assets will always come from cache) while still forcing a refresh if the asset has been updated. This post will explore best practices for fingerprinting images, but the general principles also apply to other static assets such as CSS and JavaScript files.
Implementing a caching strategy in your infrastructure simplifies caching and can remove the manual process around eviction. This assumes that your caching layer uses a least-recently-used (LRU) approach. (Most caching layers that handle web traffic do, including Imgix.) Instead of doing a manual purge of an old logo, for example, the build script could just create and append a hash of the new image contents to the filename to implicitly invalidate the cached image.
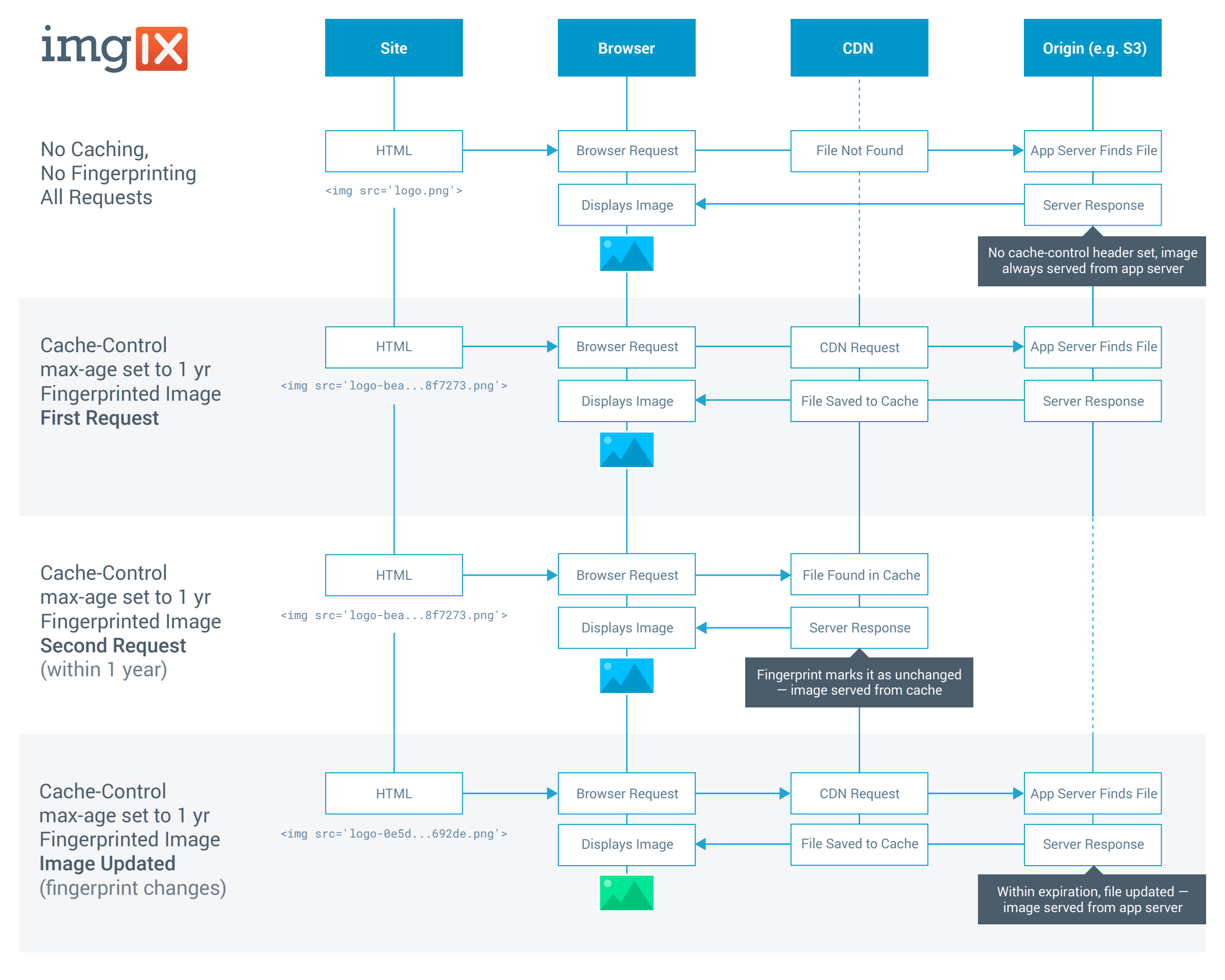
General Caching Strategy for Images
Caching is best implemented as a tiered strategy, covering two basic needs: setting an expiration date for the image and tracking when it has changed. The end goal is to minimize roundtrips to the app server and retrieve the asset from a cache whenever possible. We recommend that you fingerprint all image files and set their Cache-Control: max-age=86400. Here’s why.
HTTP headers offer two ways to set the expiration—both explicitly state how long the image can be kept in cache.
Expires: Sets an expiration date and time (in HTTP 1.1 date format, GMT time)Cache-Control: max-age=xxxx: Sets an expiration date and time in seconds
Of the two, max-age is the better choice; it’s simpler to implement and understand, and less prone to error due to formatting or time zone issues.1 For images, setting max-age to 1 year (31536000 seconds) effectively makes the expiration date infinite from a user perspective. max-age will also override Expires if both are present.
There are also two ways for HTTP headers to validate when images have been modified.
Last-Modified: Communicates the date the file was last updated on the app server (in HTTP 1.1 date format, GMT time)ETag: A unique ID generated from file metadata and node
Both are used by caches to compare the file in cache to the one on the app server without having to inspect the file itself. For load-balanced server environments (>1 node), Last-Modified is a better choice, because the different nodes can generate different ETags and create an inconsistent response across your servers.
In general, you will want to specify either Expires or max-age—specifying both would be redundant.
Note: For Imgix specifically, setting the Cache-Control header will help reduce cache misses for files that Imgix doesn’t process (like SVGs) and also prevent it from re-fetching images it does process from origin. If you’re using Amazon S3 and need to update files that are already in your bucket, you can run a script like s3cmd to set the header after uploading.
Best Practices for Fingerprinting
Images generally change less often than other types of static files like CSS and JavaScript. This means that the max-age setting in your Cache-Control headers can be high, as long as you also have a way to “bust the cache” and make sure updated images get to your users when they do change. Fingerprinting images by appending a hash of the file contents to the filename is the best way to do this, for a few reasons:
-
Creating the hash only from the file contents means that the fingerprint will be consistent across all servers in the stack, unlike the unique ID created by
Etag. -
Most modern web frameworks have helpers to create the fingerprint automatically at build time, so there’s no need to manually rename image files. (Rails example)
-
Appending the fingerprint as a query string (another common method) isn’t always recognized.2 Doing so may also conflict with Imgix’s URL parameters.
File fingerprints (or checksums) are generated by analyzing the content in a file and producing a short string of hexadecimal characters (a hash) to represent that. A checksum will look something like this: bea8252ff4e80f41719ea13cdf007273.
Checksums use a repeatable hashing strategy to generate consistent fingerprints for files, which means they are a more reliable method than simply incrementing a version number. A common hashing algorithm for generating file fingerprints is MD5. You can try MD5 out in the command line: echo "Hello, World\!" | md5.
How Fingerprinting Interacts with Imgix
Imgix strongly recommends using a fingerprinting-based approach for cache management, because it obviates the need to issue purge requests against our API. When you update a fingerprinted image, the new image will be requested from your Source because the filename has changed.
The old Origin Asset will not be counted after that because it isn’t requested anymore. Both the old and new Origin Assets will be counted toward the monthly total for billing in the month when the switch occurs, but the impact will be minimal unless you change many thousands of images over within the month. You may still want to remove the old Origin Assets from your origin storage if you’re charged for total bytes stored.
Conclusion & More Information
This is a quick overview of caching and fingerprinting—depending on your server, backend code, and caching strategy, there are even more fine-grained controls available. If you really want to dig in deep on the topic, here are a couple of comprehensive resources:
- Google Developers HTTP Caching guide
- Caching section of the HTTP/1.1 specification
- Mark Nottingham’s Caching Tutorial
Footnotes
-
Expires vs. max-age – Mark Nottingham, May 5, 2007 ↩
-
Revving Filenames: don’t use querystring – Steve Souders; August 23, 2008 ↩